ESC(Programming Lab)
-
화자인식 프로젝트 링크2020.03.13
-
k-NN (k nearest neighbor) 알고리즘 구현2020.03.10
-
Feed Foward Neural Network (Java + Matlab)2020.02.10
-
Backpropagatin Neural Network (C language)2020.02.10
-
Matrix Multiplication2019.11.30
화자인식 프로젝트 링크
https://github.com/namhj94/Speaker_Verification-based_library_seat_reservation_system
namhj94/Speaker_Verification-based_library_seat_reservation_system
Contribute to namhj94/Speaker_Verification-based_library_seat_reservation_system development by creating an account on GitHub.
github.com
https://github.com/namhj94/Speaker_Recognition_Application-based-on_Neural_Network
namhj94/Speaker_Recognition_Application-based-on_Neural_Network
Contribute to namhj94/Speaker_Recognition_Application-based-on_Neural_Network development by creating an account on GitHub.
github.com
k-NN (k nearest neighbor) 알고리즘의 병렬화 II (KNN+SIMD+Pthread)
이 문서와 동일 폴더에 있는 문서들과 샘플코드를 참고하여 POSIX thread (pthread) programming을 k-NN 코드에 적용
- SIMD를 적용하지 않은 코드에 pthread programming을 다음과 적용하여 thread의 개수를 2, 4로 변화시켜 실행시간 비교
1) 입력벡터를 2개, 또는 4개의 그룹으로 나누어 각 thread가 하나의 그룹을 담당하도록 적용
2) 기준벡터를 2개, 또는 4개의 그룹으로 나누어 각 thread가 하나의 그룹을 담당하도록 적용
SIMD를 적용한 코드에 pthread programming을 적용. 단 thread의 개수는 4개, 그리고 적용 방법은 위의 1)을 사용.

'ESC(Programming Lab) > Machine Learning' 카테고리의 다른 글
| k-NN (k nearest neighbor) 알고리즘의 병렬화(KNN+SIMD) (0) | 2020.03.12 |
|---|---|
| k-NN (k nearest neighbor) 알고리즘 구현 (0) | 2020.03.10 |
| K-means clustering (C language) (2) | 2020.02.11 |
| Feed Foward Neural Network (Java + Matlab) (0) | 2020.02.10 |
| Backpropagatin Neural Network (C language) (0) | 2020.02.10 |
k-NN (k nearest neighbor) 알고리즘의 병렬화(KNN+SIMD)
1) SIMD.pptx를 참조하여 SIMD parallelization을 k-NN 코드에 적용하여 SIMD 적용 전과 후의 실행 시간 비교
- 일단 sse_practice.c를 가지고 적용 연습을 한 후 k-NN 코드에 적용
sse_practice.c에 나온 배열을 채우는 방법을 k-NN에서 사용하면 됨 (파일을 읽는 것 대신에 임의로 큰 배열을 만들기 위해 하는 것임)
k-NN에 적용하는 경우 배열들의 크기는 다음과 같이 정해서 사용
입력벡터의 개수: 4096, 기준벡터의 개수: 2048, 벡터의 길이: 2048
sse_practice.c에서는 gettimeofday( )를 이용했지만 시간의 측정을 위해 지난 번에 사용한 함수를 사용하면 됨 (gettimeofday( )는 리눅스에서 사용한 것으로 visual studio에서는 없음).
sample 폴더에 들어있는 코드는 SVM (support vector machine)의 분류에 해당하는 코드로 SIMD 적용 전과 적용 후의 코드들임. 이 코드를 참조하여 SIMD를 적용하면 됨
실험결과로 SIMD 사용 전 후의 실행시간을 보여주면 됨
'ESC(Programming Lab) > Machine Learning' 카테고리의 다른 글
| k-NN (k nearest neighbor) 알고리즘의 병렬화 II (KNN+SIMD+Pthread) (0) | 2020.03.12 |
|---|---|
| k-NN (k nearest neighbor) 알고리즘 구현 (0) | 2020.03.10 |
| K-means clustering (C language) (2) | 2020.02.11 |
| Feed Foward Neural Network (Java + Matlab) (0) | 2020.02.10 |
| Backpropagatin Neural Network (C language) (0) | 2020.02.10 |
k-NN (k nearest neighbor) 알고리즘 구현
1) k-NN 알고리즘의 이해
- 구글드라이브 ebook 폴더에 있는 “Machine learning in action”의 chapter2나 인터넷을 이용하여 k-NN 알고리즘에 대해 이해
2) k-NN 알고리즘의 구현
- 프로그램 인수로 reference data 파일이름, test data 파일이름, k값을 받도록 작성
reference data와 test data를 파일에서 읽어 들여 저장할 배열의 크기는 이미 파일 내 데이터의 정보를 알고 있으므로 이를 이용하면 됨 (그러나 동적할당 사용).
실험에 사용할 IRIS 데이터는 https://archive.ics.uci.edu/ml/datasets/Iris 에서 다운 받을 수 있음 (UCI machine learning repository).
IRIS 데이터는 3개의 클래스가 있으며 각 클래스마다 50개의 데이터 (벡터)가 있음. 90개 (각 클래스마다 30개) 벡터를 reference data로, 나머지 60개를 테스트 데이터로 분류하여 reference data 파일, test data 파일을 만들 것.
정렬 (sorting)을 위해서는 stdlib.h에 정의되어 있는 qsort( ) 함수를 이용. 함수의 이용 방법은 인터넷 참조. Quick sorting 알고리즘에 대해서도 자료구조 수업에 사용했던 책이나 인터넷을 참고하여 이해.
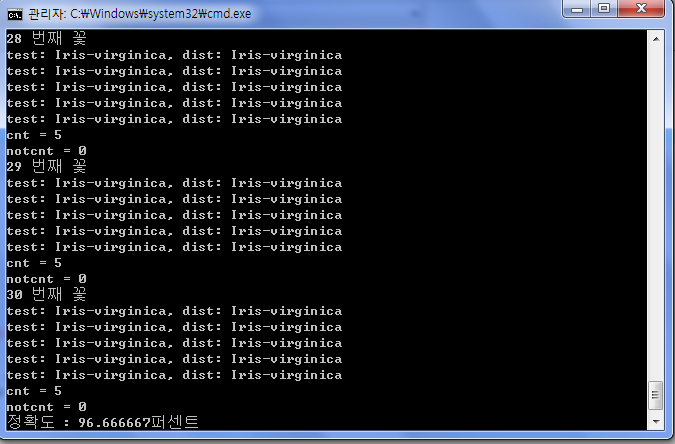
프로그램의 (모니터) 출력은 각 클래스마다 분류의 정확도를 출력 (맞게 분류된 벡터 개수/총 벡터 개수).
3) k-NN 알고리즘의 실행
k의 값을 변화시켜가며 실험을 하여 분류 정확도가 어떻게 변하는지 실험
Reference data와 test data의 비율을 3:2가 아니라 1:4, 2:2, 4:1로 변화시켜가며 실험을 하여 분류정확도가 어떻게 변하는지 실험.
'ESC(Programming Lab) > Machine Learning' 카테고리의 다른 글
| k-NN (k nearest neighbor) 알고리즘의 병렬화 II (KNN+SIMD+Pthread) (0) | 2020.03.12 |
|---|---|
| k-NN (k nearest neighbor) 알고리즘의 병렬화(KNN+SIMD) (0) | 2020.03.12 |
| K-means clustering (C language) (2) | 2020.02.11 |
| Feed Foward Neural Network (Java + Matlab) (0) | 2020.02.10 |
| Backpropagatin Neural Network (C language) (0) | 2020.02.10 |
K-means clustering (C language)
군집화 알고리즘인 K-means clustering 알고리즘을 C언어로 구현했습니다.
data set은 Iris data set을 사용했습니다.

'ESC(Programming Lab) > Machine Learning' 카테고리의 다른 글
| k-NN (k nearest neighbor) 알고리즘의 병렬화(KNN+SIMD) (0) | 2020.03.12 |
|---|---|
| k-NN (k nearest neighbor) 알고리즘 구현 (0) | 2020.03.10 |
| Feed Foward Neural Network (Java + Matlab) (0) | 2020.02.10 |
| Backpropagatin Neural Network (C language) (0) | 2020.02.10 |
| Matrix Multiplication (0) | 2019.11.30 |
Feed Foward Neural Network (Java + Matlab)
Matlab의 nprtool을 사용해 Backprop 알고리즘으로 뉴럴의 가중치를 학습하여 Java로 구현한 Feed Foward 네트워크에서 사용함으로써
학습된 네트워크 모델을 사용할 수 있다.



'ESC(Programming Lab) > Machine Learning' 카테고리의 다른 글
| k-NN (k nearest neighbor) 알고리즘의 병렬화(KNN+SIMD) (0) | 2020.03.12 |
|---|---|
| k-NN (k nearest neighbor) 알고리즘 구현 (0) | 2020.03.10 |
| K-means clustering (C language) (2) | 2020.02.11 |
| Backpropagatin Neural Network (C language) (0) | 2020.02.10 |
| Matrix Multiplication (0) | 2019.11.30 |
Backpropagatin Neural Network (C language)
기계학습 책의 오차 역전파 알고리즘을 토대로 작성, Iris data set을 사용한 성능 실험.

Pseudocord 참고문헌 : 오다카 토모히로 저, 김성재 역, 만들면서 배우는 기계 학습, 한빛 미디어, 2012
'ESC(Programming Lab) > Machine Learning' 카테고리의 다른 글
| k-NN (k nearest neighbor) 알고리즘의 병렬화(KNN+SIMD) (0) | 2020.03.12 |
|---|---|
| k-NN (k nearest neighbor) 알고리즘 구현 (0) | 2020.03.10 |
| K-means clustering (C language) (2) | 2020.02.11 |
| Feed Foward Neural Network (Java + Matlab) (0) | 2020.02.10 |
| Matrix Multiplication (0) | 2019.11.30 |
Matrix Multiplication
※ Matrix multiplicationMatrix (행렬) multiplication (programming practice #1)의 확장
과제 내용)
- 파일로부터 행렬의 값을 읽어 들이고 연산의 결과도 파일로 출력
- 특정 코드 부분의 실행시간를 측정(측정 대상: 파일로부터 행렬을 읽어들이는 부분 + 행렬의 곱을 계산하는 부분 + 행렬의 곱의 결과를 2 차원 배열에 쓰는 부분)
세부 사항)
1) 프로그램 작성
프로그램은 2가지 방법으로 작성하여 실행시간을 비교해 본다. 그리고 왜 그런지도 생각해 본다.
[방법 1]
(측정 point 1) -> 파일로부터 2차원 배열에 값을 채움 -> 행렬의 곱을 계산하고 계산 결과는 (결과 행렬의 각 원소의 값이 계산되면) 미리 선언 및 할당해둔 2차원 배열에 그때 그때 저장 -> (측정 point 2) -> 결과 파일에 2차원 배열의 값을 출력
[방법 2]
(측정 point 1) -> {첫 행렬의 행을 파일로부터 읽어 1차원 배열에 저장하고 두 번째 행렬의 열을 읽어 역시 1차원 배열에 저장한 후 벡터의 곱을 계산 (계산 결과는 결과 행렬 (미리 선언 및 할당해둔 2차원 배열)에 그때 그때 저장}을 결과 저장하는 2차원 벡터에 값이 다 찰 때까지 수행 -> (측정 point 2) -> 결과 파일에 2차원 배열의 값을 출력
[방법 1]
4*4 행렬의 연산은 크기가 작으므로 배열로 선언하면 되지만, 4096 * 4096 크기의 행렬연산은 데이터 크기가 너무 커지므로 힙(heap)영역에 공간을 동적할당(malloc)해서 처리했습니다.
4by4 c code)
4096 by 4096 c code)
실행시간 1622.253517 second
[방법 2]
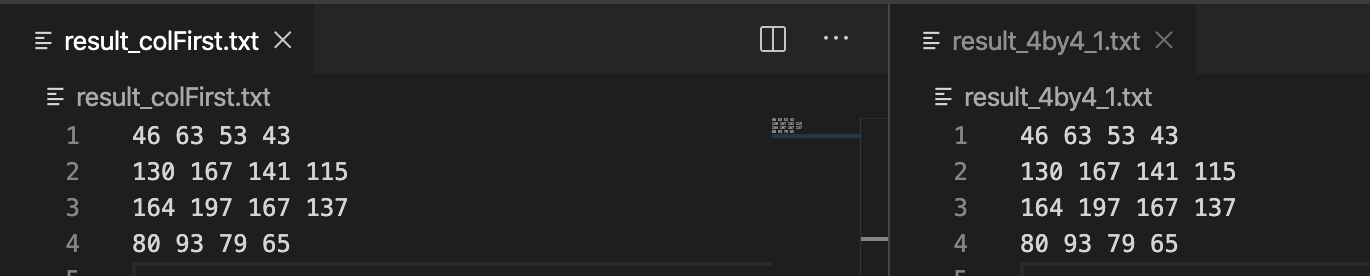
방법 2는 두번째 파일의 행렬을 열우선으로 읽어야 하기때문에, 이를 구현하고자 작은 행렬로 먼저 시도를 하였습니다.
4by4 크기의 행렬로 [방법 1]의 연산값과 [방법 2]의 연산값을 비교하여 동일한것을 확인했습니다.
* 연속된 숫자의 덧셈으로 표현하기 게임 확장
1) 대상 숫자를 받으면 그 대상 숫자를 연속된 숫자 (2개~5개)의 덧셈으로 표현하는 것을 했었는데 이번에는 대상 숫자와 연속된 숫자의 개수 를 키보드로부터 입력받아서 표현하도록 확장.
- 대상 숫자와 연속된 숫자의 개수는 임의의 양의 정수가 대입될 수 있음
연속된 숫자의 개수는 임의의 숫자이므로 어떤 개수가 입력되어도 동작하도록 일반적인 법칙을 구하여 코딩해야 함 일반적인 개수를 구할 수 없다면 다른 방법 (?!)을 생각해야 함
'ESC(Programming Lab) > Machine Learning' 카테고리의 다른 글
| k-NN (k nearest neighbor) 알고리즘의 병렬화(KNN+SIMD) (0) | 2020.03.12 |
|---|---|
| k-NN (k nearest neighbor) 알고리즘 구현 (0) | 2020.03.10 |
| K-means clustering (C language) (2) | 2020.02.11 |
| Feed Foward Neural Network (Java + Matlab) (0) | 2020.02.10 |
| Backpropagatin Neural Network (C language) (0) | 2020.02.10 |